Claims
Milliman’s predictive analytics solutions leverage advanced technology for an improved early identification of high-loss claims. Today’s advanced modeling methods provide maximum insight from existing claims data and make it possible to:
- Dramatically increase efficiency and effectiveness of high value claims personnel
- Consistently apply the best resources for improved claim triage
- Uncover claim-cost segments with previously unnoticed characteristics
- Evaluate and augment current methods
- Monitor adjuster claims handling
- Assess accuracy of case reserves
- Target specific types of claim outcomes, such as subrogation opportunities
Using machine learning methods to analyze traditional claims and policy information together with detailed medical data, Milliman is able to develop claim severity models to accurately identify:
- “Light touch” claims – early identification of low-cost claims that can be closed with little or no adjuster involvement
- “Cluster” claims – claim cohorts defined by often unnoticed combinations of characteristics that are predictive of their ultimate severity
- “Jumper” claims – early identification of claims that have a low case reserve early in their life cycle but have a high potential to become costly
Our advanced modeling techniques harness the value of all data available to provide new information targeted around specific business goals:
- Identify complex patterns in critical cost-driver characteristics
- Intervene early in the identification of high-severity claims
- Control workflow for low severity claims
- Additional support for setting case reserves
- Improve routing and handling guidelines for better claims triage strategy
- Gain early indication of claims likely to enter into litigation
- Anticipate claim timelines to spot opportunities for targeted intervention
- Increase detection of subrogation opportunities
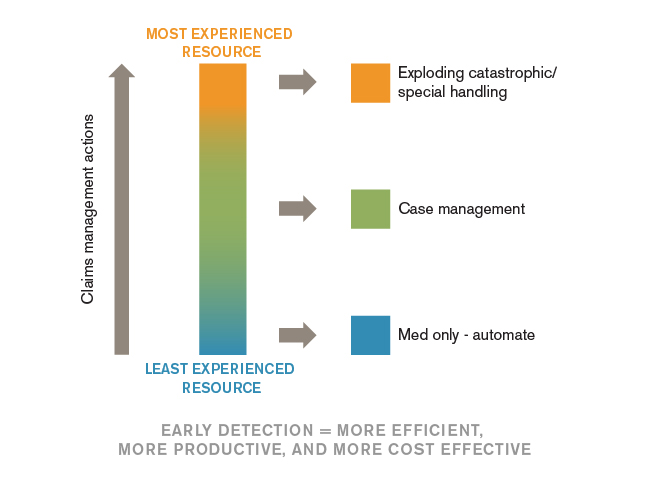
The power of these machine learning algorithms lies in their ability to efficiently analyze hundreds of characteristics and correlations, ultimately identifying combinations of factors that can produce claim scores or segment claims into different size-of-claim cost groups. The use of transactional data allows us to analyze and identify those factors that are important at different points throughout the claim life cycle. The use of text data allows us to identify claim activities (such as certain medical treatments, attorney representation, and co-morbidities). The resulting models score and rank claims by predicted ultimate severity. The modeling results also provide the statistical support to adjust claim level authorities and influence best practices (i.e., ensure claims defined by the characteristics for the highest cost clusters are assigned to the most experienced claim adjusters).
Property-casualty insurers and third-party administrators capture large amounts of useful information in first reports of injury, accident descriptions, adjusters’ notes, diary notes, medical management reports, special investigative reports, and telephone interviews. Milliman has developed software that efficiently extracts information from text data and converts this information into searchable, structured fields – making it available for statistical analysis. Milliman’s property-casualty text-mining software gives claims personnel early access to key information captured in text data long before traditional workflows discover the same information. A phrase dictionary developed specifically for the property-casualty industry assures accurate and actionable findings. Ultimately, text mining can lead to greater efficiency in the adjustment process and to better—and quicker—positive financial outcomes for insurers.